Qual a melhor métrica para avaliar os modelos de Machine Learning?


As métricas de validação apresentam o desempenho do modelo treinado em dados desconhecidos e analisar essas métricas é tão importante quanto a preparação dos dados e o ajuste do modelo de Machine Learning,
Mas entre tantas métricas qual é a melhor métrica para avaliar os modelos de classificação?
Depende, ao avaliar por exemplo a acurácia podemos ter uma falsa impressão que o modelo está satisfatório, porém quando utilizamos outra métrica o modelo apresenta uma performance ruim.
Assim, o melhor é sempre utilizar mais de uma métrica para garantir que não exista nenhum problema na predição do seu modelo.
Nesse artigo, vamos discutir e apresentar as principais métricas dos modelos de classificação e discutir quando é melhor utilizar uma ao invés da outra.

Mas o que são métricas de validação de modelo?
As métricas de validação são utilizadas para analisar a qualidade dos modelos de Machine Learning. Ou seja, traz a informação do desempenho do modelo em dados desconhecidos.
Lembre-se, nos modelos de aprendizado supervisionado o objetivo é tentar estimar (prever) uma determinada variável. Por exemplo, classificar se um e-mail é Spam ou Não.
Assim, analisando as diferentes métricas de validação dos modelos conseguimos analisar o poder preditivo do mesmo, antes de colocar em produção.
Já pensou fazer um modelo que consiga prever 99% dos dados e quando você entrega para seu superior ou cliente, o modelo não consegue acertar nada. Imagina o prejuízo financeiro da empresa e da sua reputação.
Existem diferentes métricas e algumas funcionam melhor para um determinado problema. Escolher uma boa métrica para avaliar o modelo é tão importante quanto escolher um bom modelo. Nos modelos de classificação a maioria das métricas são baseadas na matriz de confusão.
OBS: Utilizo a palavra prever para ajudar no entendimento do conceito, mas a palavra correta é estimar. Os modelos de classificação estimam uma probabilidade da observação pertencer a uma classe. Quanto mais alta essa probabilidade, maior a chance da observação pertencer aquela classe.
O que é matriz de confusão?

Matriz de confusão é uma matriz que traz a informação de todos os acertos e erros do modelo ao prever as classes. Como seu nome já diz, sempre causa uma confusão na cabeça das pessoas, mas vamos tentar explicar de uma maneira simples.
A matriz de confusão é a matriz quadrada em que se compara os verdadeiros valores de uma classificação com os valores preditos através de algum modelo. Sua diagonal é composta pelos acertos do modelo e os demais valores são os erros cometidos. O caso binário, o mais comum, é representado pela seguinte matriz:

Imagine que você precise de um modelo que possa classificar se uma pessoa está grávida.
O modelo de classificação será treinado com vários exemplos de pessoas grávidas e pessoas que não estão grávidas. E a partir dessas informações prévias tenta “prever” se uma nova paciente está grávida ou não.
Para analisar se o modelo é capaz de “prever” se uma pessoa está grávida, preciso testar em novos dados que não foram utilizados no treinamento (aprendizado) do modelo. Para isso, utilizo observações (dados) que tenho a reposta (grávida ou não grávida) e analiso os resultados que o modelo estimou com os resultados que tenho.
A matriz de confusão é uma maneira de exemplificar esses resultados e ela nos traz as informações das frequências dos acertos e erros do modelo. Ou seja, nos mostrará as frequências:
Verdadeiro Negativo (VN): são as observações que o modelo previu como negativas e realmente eram negativas, ou seja, o modelo classificou corretamente. Por exemplo, a pessoa não está grávida e o modelo conseguiu identificar corretamente.
Falso Positivo (FP): são as observações que o modelo previu como positivas, mas na realidade eram negativas. Ou seja, o modelo estimou errado a classe que temos interesse em estimar. Por exemplo, a pessoa não está grávida e o modelo prevê como grávida.
Falso Negativo (FN): são as observações que o modelo identificou como negativas, mas eram positivas. Ou seja, as observações que o modelo estimou errado . Por exemplo, a pessoa está grávida e o modelo classifica como não grávida.
Verdadeiro Positivo: são as observações que são positiva e o modelo consegue classificar corretamente. Ou seja, as observações, da classe de interesse, que o modelo classificou corretamente. Por exemplo, a pessoa está grávida e o modelo consegue classificar como grávida.
Acurácia
Acurácia é a métrica mais simples, ela representa o número de previsões corretas do modelo. Ótima métrica para utilizar quando os dados estão balanceados, vai dar uma visão geral do quanto o modelo está identificando as classes corretamente.
Porém, não devemos utilizar a acurácia, quando temos classes desbalanceadas, causa uma falsa impressão de bom desempenho.
Por exemplo: considere um estudo em que apenas 5% da população apresenta uma determinada doença. Logo, temos um conjunto de dados desbalanceado.
Se o modelo escolhido conseguir classificar corretamente todas as pessoas que não tem a doença e errar a classificação de todos os doentes, teremos uma acurácia de 95%. Dando uma falsa impressão que o modelo treinado tem uma ótima previsão. Porém, o modelo não consegue classificar corretamente a classe de interesse.

Valor Preditivo Negativo
Valor Preditivo Negativo (VPN) é a métrica que traz a informação da quantidade de observações classificadas como negativa (0) que realmente são negativa. Ou seja, entre todas as observações prevista como negativa (0), quantas foram identificadas corretamente.
Por exemplo: entre os pacientes classificados como não doentes, quantos foram identificados corretamente. 
Precision
Precision ou precisão, também conhecida como Valor Preditivo Positivo (VPP), é a métrica que traz a informação da quantidade de observações classificadas como positiva (1) que realmente são positiva. Ou seja, entre todas as observações identificadas como positivas (1), quantas foram identificadas corretamente.
Por exemplo: entre os pacientes classificados como doentes, quantos foram identificados corretamente.
Recall
Recall ou Sensibilidade é a proporção dos Verdadeiros Positivos entre todas as observações que realmente são positivas no seu conjunto de dados. Ou seja, entre todas as observações que são positivas quantas o modelo conseguiu identificar como positiva. Representa a capacidade de um modelo em prever a classe positiva.
Por exemplo: dentre todos os pacientes doentes, quantos pacientes o modelo conseguiu identificar corretamente.

Especificidade
Especificidade é a proporção dos Verdadeiros Negativos entre todas as observações que realmente são negativas no seu conjunto de dados. Ou seja, entre todas as observações que são negativas, quantas o modelo conseguiu prever como negativa. Representa a capacidade de um modelo em prever a classe negativa.
Por exemplo: dentre todos os pacientes não doentes, quantos foram classificados corretamente.

F1- Score
F1-Score é a média harmônica entre o recall e a precisão (precision). Utilizada quando temos classes desbalanceada.

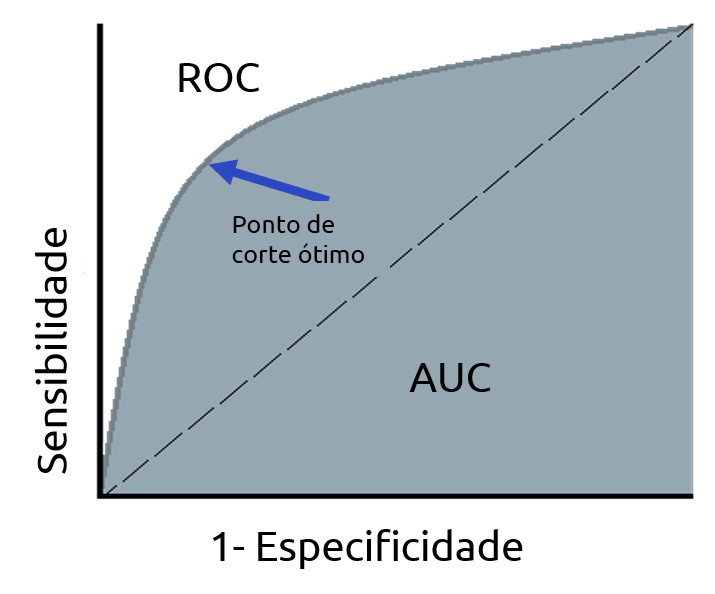
Área sob a Curva ROC
A curva ROC (Receiver Operating Characteristic Curve) é a curva gerada pela taxa de verdadeiros positivos (sensibilidade) e pela taxa de falsos positivos (1 – especificidade) para diferentes pontos de cortes (c).
A curva ROC oferece uma visão geral de um classificador e pode ser utilizada para encontrar pontos de corte ideias. O corte que deixa a curva mais próxima do vértice (0, 1) maximiza a sensibilidade conjuntamente com a especificidade.
Uma medida decorrente da curva ROC é o AUC (Area Under the Curve), que nada mais é que a área abaixo da curva. O AUC varia entre 0 e 1 e quanto maior o AUC melhor o modelo.
Utilizada quando temos classes desbalanceada e sua principal vantagem é poder escolher o melhor ponto de corte para otimizar o desempenho do modelo.
Todas essa métricas variam no intervalo [0,1] e quanto mais próximos de 1, melhor é o modelo.
Conclusão
Fora essas métricas existem muitas outras que auxiliam na escolha do melhor modelo e dão uma visão geral de como seu modelo se comporta em dados desconhecidos. Quer aprender como calcular essas métricas no Python, dá uma olhada no nosso próximo artigo.
Deixe um comentário se tiver alguma dúvida ou se conhece outra métrica. Nos ajude a melhorar o blog e levar mais conhecimento em Data Science para mais pessoas.
[Como calcular as métricas de validação no Python]
Referência
https://www.kdnuggets.com/2020/05/model-evaluation-metrics-machine-learning.html





Minha dúvida é qual metrica que pode ser utilizada em modelos de rna para regressão com mais de 3 saidas.
Para modelo de regressão são as mesmas métricas utilizadas nos modelos de regressão convencionais. Você pode utilizar o erro quadrático médio (mean squared error (MSE)), ou o coeficiente de determinação (R^2), entre outros.